
티스토리 뷰
Detecting Human Body Poses in an Image
이미지로부터 사람 신체동작 감지하기
PoseNet 모델을 활용해서 이미지를 분석하고 사람과 그들의 포즈를 알아낼 수 있습니다.
Overview
개요
해당 샘플 프로젝트에서는 PoseNet 모델을 사용해서 카메라로부터 얻은 비디오 스트림을 증강하는 방법을 보여줍니다. PoseNet 모델은 17가지의 신체, 관절을 감지합니다. (눈, 귀, 코, 어깨, 엉덩이, 팔꿈치, 무릎, 손목, 발목 등) 집합적으로 해당 관절들은 특정 포즈를 형성하게 됩니다.
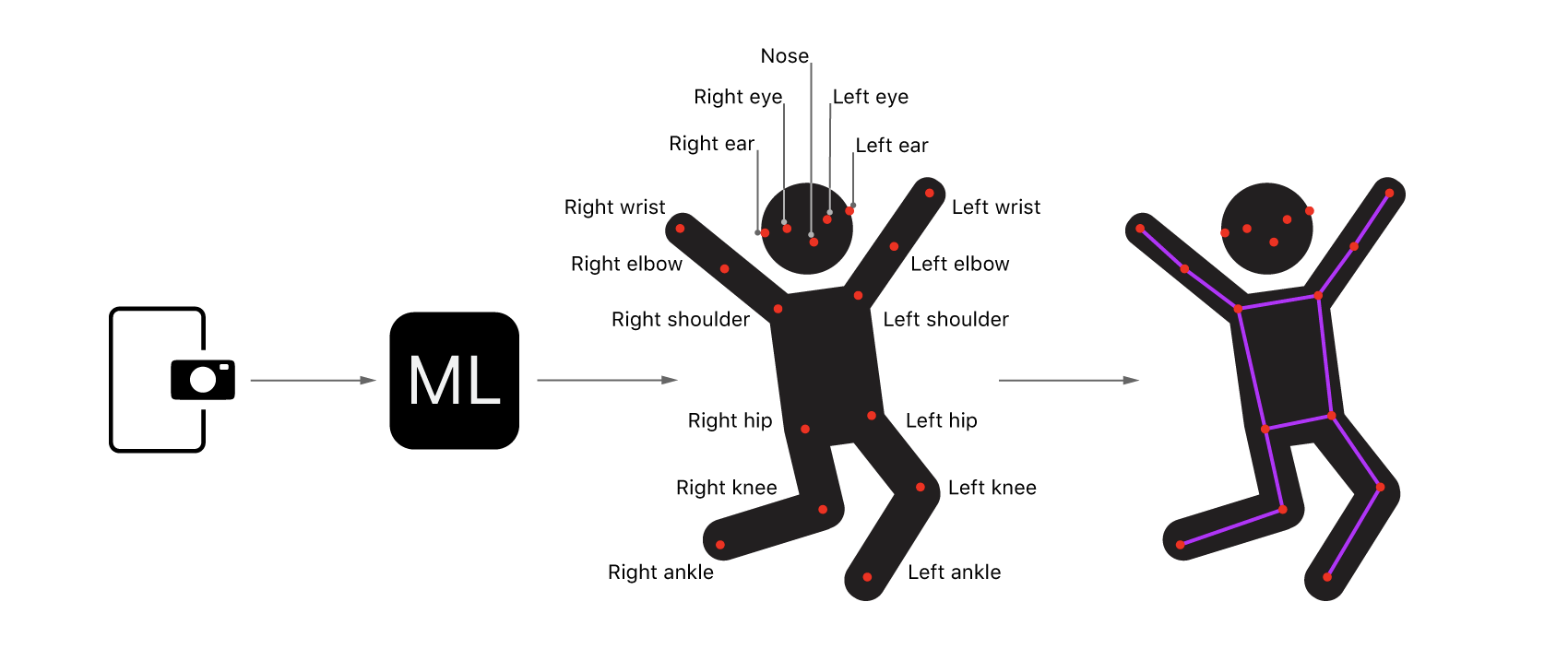
샘플 프로젝트에서는 이미지 내 각각의 사람에 대한 17가지 관절 위치를 찾고 그들의 위에 와이어프레임 포즈를 그리게 됩니다.
Note : 샘플은 iOS13 버전 이후, iPadOS13 이후의 버전 기기에서 실행해야 정상적으로 사용할 수 있습니다.
Configure the Capture Session
Capture Session 구성하기
해당 샘플 프로젝트는 AVCaptureSession을 사용한 내장 카메라에서 이미지를 가져오는 것부터 시작합니다. (Setting Up a Capture Session 을 참고하세요.)
if captureSession.isRunning {
captureSession.stopRunning()
}
captureSession.beginConfiguration()
captureSession.sessionPreset = .vga640x480
try setCaptureSessionInput()
try setCaptureSessionOutput()
captureSession.commitConfiguration()
Acquire the Captured Image
촬영된 이미지 흭득하기
Video Capture Session은 각각의 이미지를 VideoCapture 클래스의 captureOutput(_:didOutput:from:) 메서드로 전달합니다. 이때 앱에서는 받은 CMSampleBuffer가 VideoCapture 객체로 할당 된 델리게이트에 전달하기 전, CGImage로 변환합니다.
// 이미지 버퍼 메모리 접근을 위해 이미지 버퍼 잠금을 시도합니다.
guard CVPixelBufferLockBaseAddress(pixelBuffer, .readOnly) == kCVReturnSuccess
else {
return
}
// CoreGraphics(CG) 이미지 placeholder를 생성합니다.
var image: CGImage?
// pixel buffer로부터 Core Graphics bitmap image를 생성합니다.
VTCreateCGImageFromCVPixelBuffer(pixelBuffer, options: nil, imageOut: &image)
// image buffer를 해제합니다.
CVPixelBufferUnlockBaseAddress(pixelBuffer, .readOnly)
DispatchQueue.main.sync {
delegate.videoCapture(self, didCaptureFrame: image)
}
Prepare the Input for the PoseNet Nodel
PoseNet 모델에 대한 입력 준비하기
앱은 캡쳐 된 이미지를 받은 이후, 해당 이미지를 특정 크기로 리사이징 하기 위해 커스텀 기능 제공자인 PoseNetInput 인스턴스 내에서 래핑합니다.
// Wrap the image in an instance of PoseNetInput to have it resized
// before being passed to the PoseNet model.
// PoseNet 모델에 이미지를 전달하기 전, 리사이즈를 위해 PoseNetInput 인스턴스 내에 이미지를 래핑합니다.
let input = PoseNetInput(image: image, size: self.modelInputSize)
Pass the Input to the PoseNet Model
입력 내용을 PoseNet Model로 전달하기
이후 샘플 앱은 포즈를 감지하기 위해 사용되는 결과값들을 얻기 위해 입력데이터를 PoseNet 모델의 prediction(from:) 메서드로 전달하게 됩니다. 그 과정은 아래와 같습니다.
guard let prediction = try? self.poseNetMLModel.prediction(from: input) else {
return
}
그 다음, 샘플앱은 결과값이 분석 목적으로 할당 된 델리게이트에 전달되기 전, PoseNetOutput 인스턴스 내에서 모델의 입력크기, 출력 폭에 맞게 PoseNet 모델 결과값을 래핑합니다.
let poseNetOutput = PoseNetOutput(prediction: prediction,
modelInputSize: self.modelInputSize,
modelOutputStride: self.outputStride)
DispatchQueue.main.async {
self.delegate?.poseNet(self, didPredict: poseNetOutput)
}
Analyze the PoseNet Output to Locate Joints
관절 정보를 찾기 위해 PoseNet 모델 결과 값 분석하기
샘플 프로젝트에서는 한 사람 혹은 다수의 사람들에 대한 관절 정보를 찾기 위해서 두 개의 알고리즘 중 하나를 사용합니다.
첫번째 알고리즘인 The single-person 알고리즘은 가장 단순하고 가장 빠른 알고리즘으로 가장 두드러지는 관절 정보를 이미지상에서 찾기 위해 모델의 결과값을 검사하고 이를 통해 얻는 관절 정보를 사용해 단일 포즈를 만들게 됩니다.
// MARK: - 첫번째 알고리즘
// MARK: 단일 사람에 대한 포즈 감지를 위해 사용합니다.
var pose = Pose()
// For each joint, find its most likely position and associated confidence
// by querying the heatmap array for the cell with the greatest
// confidence and using this to compute its position.
// 각각의 관절에 대해 가장 유사한 위치와 관련 신뢰도를 찾습니다.
// 가장 큰 신뢰도를 가진 heatmap 배열 셀 위치를 계산하도록 합니다.
pose.joints.values.forEach { joint in
configure(joint: joint)
}
// Compute and assign the confidence for the pose.
// 포즈에 대한 신뢰도를 계산 및 할당합니다.
pose.confidence = pose.joints.values
.map { $0.confidence }.reduce(0, +) / Double(Joint.numberOfJoints)
// Map the pose joints positions back onto the original image.
// 원본 이미지 위에 관절 포즈를 매핑합니다.
pose.joints.values.forEach { joint in
joint.position = joint.position.applying(modelToInputTransformation)
}
return pose

두번째 알고리즘인 multiple-person 알고리즘은 먼저 시작점으로서 후보 루트 관절 셋을 식별합니다. 이때 얻는 루트 관절들은 인접한 관절들을 찾고, 각 사람 마다 17가지의 모든 관절을 찾을 때까지 반복하여 작업합니다.
예를들어, 해당 알고리즘은 높은 신뢰도로서 좌측 무릎을 찾을 수 있으며 이후 이에 인접한 관절인 발목인 왼쪽 엉덩이를 찾아낼 수 있을 것입니다.
// MARK: - 두번째 알고리즘
// MARK: 다수의 사람에 대한 포즈 감지를 위해 사용합니다.
var detectedPoses = [Pose]()
// Iterate through the joints with the greatest confidence, referred to here as
// candidate roots, using each as a starting point to assemble a pose.
// 포즈를 반들기 위해 각각의 시작점을 사용해서 후보 루트로서 참고되는 가장 높은 신뢰도에 따라 관절을 순회합니다.
// ex) 어떤 사람의 무릎 관절이 시작점이라면 점점 뻗어가는 방식
for candidateRoot in candidateRoots {
// Ignore any candidates that are in the proximity of joints of the
// same type and have already been assigned to an existing pose.
// 관절을 찾는 중 근접한 관절들이 같은 유형이고 이미 현재 포즈에서 할당되거나 존재하는 관절일 경우에는 무시합니다.
let maxDistance = configuration.matchingJointDistance
guard !detectedPoses.contains(candidateRoot, within: maxDistance) else {
continue
}
var pose = assemblePose(from: candidateRoot)
// Compute the pose's confidence by dividing the sum of all
// non-overlapping joints, from existing poses, by the total
// number of joints.
// 포즈의 신뢰도에서 아직 할당되지 않은 관절들의 총 합을 나누는 연산을 합니다.
pose.confidence = confidence(for: pose, detectedPoses: detectedPoses)
// Ignore any pose that has a confidence less than the assigned threshold.
// 신뢰도 기준을 충족하지 못하는 포즈는 무시합니다.
guard pose.confidence >= configuration.poseConfidenceThreshold else {
continue
}
detectedPoses.append(pose)
// Exit early if enough poses have been detected.
// 충분한 포즈가 발견되었다면 조기에 종료합니다.
if detectedPoses.count >= configuration.maxPoseCount {
break
}
}
// Map the pose joints positions back onto the original image using
// the pre-computed transformation matrix.
// 미리 연산된 변형 매트릭스를 사용해서 원본 이미지 위에 포즈를 매핑합니다.
detectedPoses.forEach { pose in
pose.joints.values.forEach { joint in
joint.position = joint.position.applying(modelToInputTransformation)
}
}
return detectedPoses

Visualize the Detected Poses
감지된 포즈를 시각화 하기
샘플 앱에서는 감지 된 각 포즈에 대해 입력 받았던 이미지 위에 와이어프레임을 그리는데, 각각의 관절 사이에 라인을 그려줍니다. 또한 이때 각각의 관절 위치에는 원을 표시해줍니다.

let dstImageSize = CGSize(width: frame.width, height: frame.height)
let dstImageFormat = UIGraphicsImageRendererFormat()
dstImageFormat.scale = 1
let renderer = UIGraphicsImageRenderer(size: dstImageSize,
format: dstImageFormat)
let dstImage = renderer.image { rendererContext in
// Draw the current frame as the background for the new image.
// 새로운 이미지를 위한 배경으로서 현재 프레임을 그려줍니다.
draw(image: frame, in: rendererContext.cgContext)
for pose in poses {
// Draw the segment lines.
// 각각의 조각 라인을 그러줍니다.
for segment in PoseImageView.jointSegments {
let jointA = pose[segment.jointA]
let jointB = pose[segment.jointB]
guard jointA.isValid, jointB.isValid else {
continue
}
drawLine(from: jointA,
to: jointB,
in: rendererContext.cgContext)
}
// Draw the joints as circles above the segment lines.
// 발견된 관절에 대해서 원으로 표시해줍니다.
for joint in pose.joints.values.filter({ $0.isValid }) {
draw(circle: joint, in: rendererContext.cgContext)
}
}
}
Detecting Human body poses in an image 원문 링크 ▼
Detecting Human body poses in an image
'iOS 개발 > 개발자문서 정보' 카테고리의 다른 글
| iOS Vision, VNImageRequestHandler 개발자문서 개요 (0) | 2020.05.24 |
|---|---|
| iOS Swift Dictionary, 딕셔너리 개발자 문서 개요 (2) | 2020.05.10 |
| iOS NLTokenizer로 자연어 텍스트 토큰화하는 방법 (0) | 2020.05.04 |
| iOS ML모델 생성 및 학습 도구, CreateML 문서 개요 (0) | 2020.05.02 |
| iOS CoreML 자연어처리(Natural Language) 개요 (0) | 2020.05.01 |
- Total
- Today
- Yesterday
- swift concurrency
- SwiftUI
- swift 문자열
- swift알고리즘
- 알고리즘문제
- 개발자문서
- swift문제
- swift reduce
- Swift 알고리즘
- 부스트코스
- 프로토콜
- 프로그래머스
- swift
- 백준swift
- CoreML
- 알고리즘
- 컬렉션
- Collection
- 자연어처리
- 스위프트
- 백준알고리즘
- Protocol
- createML
- 프로그래머스swift
- swift언어
- swift 기초
- 김프매매
- uikit
- swift string
- ios
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |